Very recently I have written a post on fdupes utility which is used to find and replace duplicate files in Linux. This post was very much liked by our readers. If you have not gone through the fdupes utility post, you may like to go through it here:
- fdupes Tool to Find and Delete Duplicate Files
This post aims at throwing light on what is fslint, its features, installation and usages.

What is fslint?
fslint is a Linux utility to remove unwanted and problematic cruft in files and file names and thus keeps the computer clean. A large volume of unnecessary and unwanted files are called lint. fslint remove such unwanted lint from files and file names. Fslint help fight against unwanted files by coping with duplicate files, empty directories and improper names.
Features of fslint
- It is a combination of different tools that look after duplicate files, empty directories and improper name.
- Simple GTK+ Graphic front-end as well as command-line.
- Fslint cope with lint that relates to Duplicate files, Problematic filenames, Temporary files, Bad Symlinks, Empty directories and Non-stripped binaries.
- Help you in reclaiming disk space that were used by unnecessary and unwanted files.
Install fslint on a Linux
Installation of latest version of fslint package can be installed as easy as executing following command onDebian based systems such as Ubuntu and Linux Mint.
$ sudo apt-get install fslint
On CentOS/RHEL based distributions, you need to active epel repository to install fslint package.
# yum install fdupes
# dnf install fdupes [On Fedora 22 onwards]
How do I use fslint Command?
Hope you know one of the basic rule of computation and understand the risk – have backup. Before you start testing this application make sure you have backup of everything on your system, so that even if an important file gets deleted you may restore almost immediately.
Now as you know that fslint is one such application that has a command-line interface as well as a front-end GUI at the same time. You may use either.
For developers and administrators, CLI version is preferred as it gives you immense power. GUI front-end is best suited to newbies and those who prefer GUI over CLI.
fslint Command Line Usage
The command line version of fslint is not on the path of most of the Linux users. You may access it at the location /usr/share/fslint/.
$ ./usr/share/fslint/fslint/fslint
Sample Output
-----------------------------------file name lint ./.config/google-chrome/Default/Pepper\ Data/Shockwave\ Flash/WritableRoot/#SharedObjects/NNPAG57S/videos.bhaskar.com/[[IMPORT]] ./Documents/.~lock.fslint\ -\ Remove\ duplicate\ files\ with\ fslint\ (230).odt#
./Documents/7\ Best\ Audio\ Player\ Plugins\ for\ WordPress\ (220).odt
./Documents/7\ Best\ WordPress\ Help\ Desk\ Plugins\ for\ Customer\ Support\ (219).odt .
./Documents/A\ Linux\ User\ using\ Windows\ (Windows\ 10)\ after\ more\ than\ 8\ years(229).odt ./Documents/Add\ PayPal\ to\ WordPress(211).odt ./Documents/Atom\ Text\ Editor\ (202).odt ./Documents/Create\ Mailchimp\ account\ and\ Integrate\ it\ with\ WordPress(227).odt ./Documents/Export\ Feedburner\ feed\ and\ Import\ it\ to\ Mailchimp\ &\ setup\ RSS\ Feed\ Newsletter\ in\ Mailchimp(228).odt ----------------------------------DUPlicate files
Job 7, “/usr/share/fslint/fslint/fslint” has stopped
Important: Two things you should be kept in mind at this point. First fslint don’t delete any file on its own, It just shows you the lint files, their location and their name. You have to decide what to do with them. Second is fslint by default start searching from your ‘/home’ directory.
To search a different other than your /home directory, you must pass the directory name with the command, as:
$ /usr/share/fslint/fslint/fslint /home/avi/Pictures

To search recursively to all the sub-folders, you should use flag ‘-r’, simply as:
$ /usr/share/fslint/fslint/fslint -r /home/avi/Music/

fslint GUI Usage
You may fire the GUI Application built on top of fslint by typing fslint from Linux terminal or from theApplication Menu.
$ fslint-gui
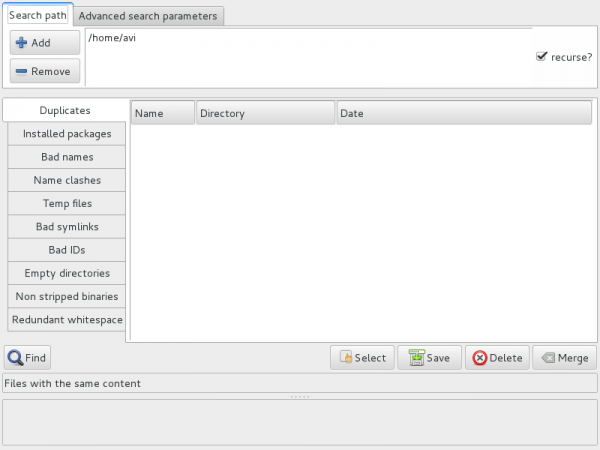
Everything in GUI is simple to understand. All you need to do is:
- Add/remove the directories to scan.
- Select to scan recursively or not by checking/unchecking checkbox on the top-right.
- Click on ‘Find’. And all done!
Again you should remember, this utility do not delete the lint files but provide you with the information only and leaves everything on you.
Conclusion
fslint is a perfect tool that remove lint of various types from a file system. Though it needs improvement in certain gray areas: –
- A bit slow for duplicate photo detection.
- Requires some improvement in User Interface.
- No Progress meter.
Hope you liked the post. If yes! Be audible. Post your valuable feedback in the comments below. Stay tuned and connected to Tecmint while I am working on another post you will love to read. Like and share us and help us get spread.